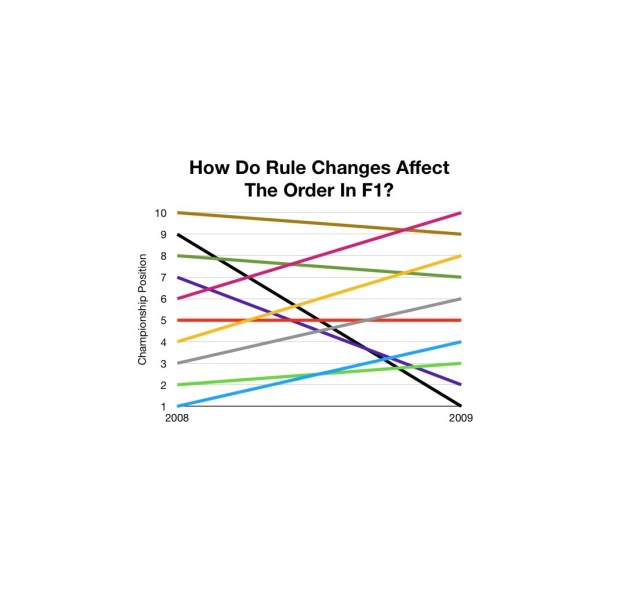
How significantly do rule changes impact the competitive order in F1? By analysing the last 6 major F1 rule changes, we can see common trends. With brand new engine and aerodynamic regulations for 2026, let’s look at what the last 30 years of F1 history tells us.
- Championship winners after rule changes
- What about the field in general?
- Do Teams Follow Simple Trends?
- Predictions for F1 2026
- Summary
Theres’s no accepted definition of what constitutes a “major” regulation change. For this article, we’ll be looking the rule changes in 1998, 2005, 2009, 2014, 2017 and 2022 seasons. All of these featured significant changes (typically to the aerodynamics, although significant tyre and engine changes also feature).
Championship winners after rule changes
It’s a common trope that rule changes knock the top team off their perch. But how true is it? Let’s see how the previous year’s constructor’s champions have done after a major rule change:
| YEARS | PREVIOUS CHAMPIONSHIP WINNING TEAM | WINS BEFORE CHANGE | WINS AFTER CHANGE | Championship position after change |
|---|---|---|---|---|
| 1997-1998 | Williams | 8 | 0 | 3rd |
| 2004-2005 | Ferrari | 15 | 1 | 3rd |
| 2008-2009 | Ferrari | 8 | 1 | 4th |
| 2013-2014 | Red Bull | 13 | 3 | 2nd |
| 2016-2017 | Mercedes | 19 | 12 | 1st |
| 2021-2022 | Mercedes | 9 | 1 | 3rd |
Every championship winning team has taken a tumble after a rule change, typically down to the upper midfield. The number of wins is quite revealing, demonstrating just how far the previous championship winning team fell. The main oddity is that Mercedes were able to continue with their championship success following on from 2016. However it even then they faced a much sterner challenge to retain the title.
Also important is how long the recovery is. Discarding Mercedes in 2017, almost every team’s fall was long-term. Williams and Ferrari have arguably yet to recover from the 1998 and 2005 rule changes. Similarly Red Bull took almost a decade to return to their best after the 2014 changes. Only Ferrari in 2005 were able to recover quickly. In that case, the biggest rule changes (the banning of tyre changes) was reversed the following year.
In this context, the “surprise” of Mercedes struggling in 2022 is actually pretty typical. As is their continued struggles for the rest of the rule era. This is obviously bad news for McLaren!
How Did The Winners Perform Before the Rule Changes?
Whilst the above is bad news for current constructor’s champions McLaren, let’s see who’s historically benefited from the new rules:
| YEARS | NEW TEAM CHAMPIONS | WINS BEFORE CHANGE | wins after change | championship position before change |
|---|---|---|---|---|
| 1997-1998 | McLaren | 3 | 9 | 4th |
| 2004-2005 | Renault | 1 | 8 | 3rd |
| 2008-2009 | Brawn | 0 | 8 | 9th |
| 2013-2014 | Mercedes | 3 | 16 | 2nd |
| 2016-2017 | Mercedes | 19 | 12 | 1st |
| 2021-2022 | Red Bull | 11 | 17 | 2nd |
Almost all winning teams under new rules were at least semi-competitive in the previous season.
One thing to note is that the recent trend is leaning towards more successful teams increasing their success. The obvious exception is the Honda-Brawn transition in 2009. This indicates that their fairy-tale story would have been remarkable even if the Honda team had stayed in the sport.
What about the field in general?
The graphs illustrate the amount of movement going on within each rule change. The left half of each graph represents the years before the rule change. The right hand side represents the year of the rule change itself. We can therefore see how impactful each rule change was.
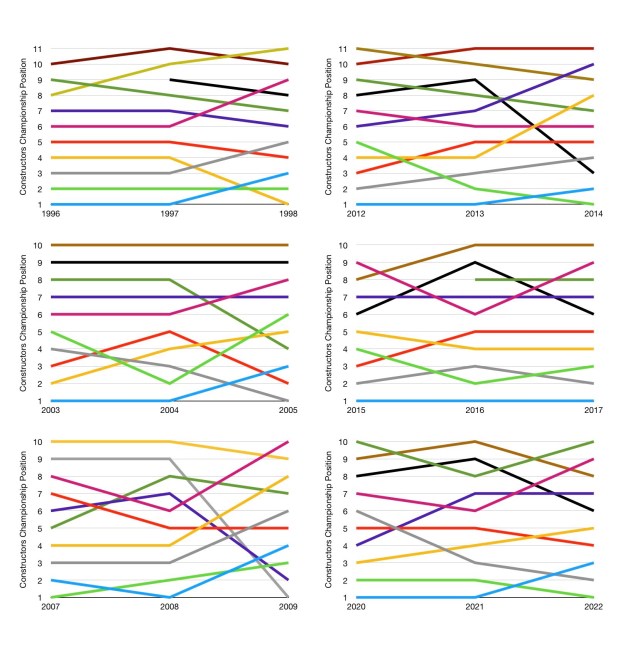
Note that several team changes occurred during these years. I have done my best to reflect this accurately in the data. Brawn GP, for example, are seen as a direct continuation of Honda. For 2007 I have added McLaren’s DSQ back in, as the aim of the graphs was to visually represent the form of teams.
The Effect of Each Rule Change
1996-1998
For 1997, the first 7 teams finished in exactly the same order as in 1996. For 1998, almost every single team changed championship position, although the changes are mostly just one or two positions.
2003-2005
The lower half of the grid is extremely stable from 2003-2004, with some movement in the upper half. This continued for 2005, with slightly larger levels of movement.
2007-2009
There is some change across 2007-2008, with a lot of movement in the lower midfield. However, no rule changes in recent memory shook up the order like 2009. Brawn (Honda) and Red Bull leaping up the field whilst Toro Rosso and Renault plummeted. This is the only rule change to truly reshuffle the order. The effect was even larger in the first half of the season. The previously dominant Ferrari and McLaren had disastrous starts but were able to (partially) recover as the season progressed.
2013-2014
The 2014 rule changes were dominated by the hybrid engines. The teams that had the Mercedes engine generally improving, and the rest of the field falling back. The level of change is comparable to the other previous rule changes.
2016-2017
2017 featured very little movement up/down the grid. In fact the order was actually more stable than in the previous year of relatively continuous rules! As with the changes in 1998, there is a clear distinction between “big teams” and “smaller teams”, with no team in the bottom 5 able to progress up to the top 5.
2021-2022
Again, the see a clear split between the big and small teams. The new rules did not allow any lower midfield teams to truly leap upwards. However, we do see more movement than usual, as the order within the lower midfield in particular was significantly shuffled.
Overall
It’s clear that the amount of reshuffling varies significantly with each rule change, and not necessarily in a predictable way. 2009 featured a significant upheaval of the grid order, whereas 2017 did not. Whilst it might be tempting to assume that this was because the 2017 rule changes were less significant, this is not how they were viewed at the time.
In years before major rule changes, teams rarely make significant moves up or down the grid across 1 year. In fact half of the time a team will finish in the same position as the previous year.
For years with rule changes, there is more scope for significant grid movement. Dramatic movements (more than 3 places) go from being completely unheard of to merely unlikely. It’s worth noting that minimal movement is still the most common outcome though. Most of the team a team will finish within 1 place of the standing in the previous year, regardless of rule changes.
Do Teams Follow Simple Trends?
It would be nice to see if improvements in form could be predicted based on previous performances. For example, could Mercedes dominance in 2014 be predicted from the improvements they made in 2013? From just looking at the data, the answer is “no”. Whilst their are other examples that support this case (e.g. Renault’s improved form in 2004 before winning both titles in 2005), the reality is far more nuanced.
There are many counter examples of teams seemingly on an upwards swing, only to fall back due to rule changes. The best example of this is Toro Rosso enjoying their most successful season in 2008 before their least successful season in 2009. Meanwhile, 2009 title winners Brawn remained languishing in 9th place in 2008 (as Honda). Fellow title challengers Red Bull actually fell back in 2008 before their leap up the order.
Those looking closely behind the scenes in 2009 may have noticed that both Honda/Brawn and Red Bull had made major hiring in the years prior. (Ross Brawn and Adrian Newey respectively.) They had also underperformed significantly in 2008, making an improvement likely. Meanwhile, Toro Rosso had lost their star driver (Vettel) and had over performed in 2008, making a fallback likely. These things tend to become clear in hindsight. However, a 2009 title challenge for Red Bull or Honda would have been seen as unlikely during the 2008 season.
Predictions for F1 2026
It’s clear that there are some general trends in the data, but nothing approaching a hard and fast rule on how a team’s form will change between 2025 and 2026.
Let’s start with the most clear result. There is a very small chance of any team outside the top 4 rising to the top. In the very unlikely scenario is which this does occur, it would be due to the whole order being reshuffled as opposed to simply one team rising through the order.
Between the top 4 teams the data suggests that McLaren are the most likely to fumble. Only Mercedes in 2016 retained their title following major rule changes, and they were far more dominant in 2016 than McLaren were last year. More alarmingly for McLaren, any fall is likely to take several seasons to overcome.
Mercedes, Ferrari and Red Bull are all theoretically well placed to statistically benefit from rule changes. However, I’d personally argue Mercedes are best placed. Their 2025 season best mirrors McLaren in 1997, Renault in 2004 and Mercedes in 2013.
For teams below the top 4, a championship challenge is unlikely, but most of the rest of the grid has the potential to improve. All will be aiming for more going into the new season, and of course several will be disappointed.
Aston Martin have big ambitions for 2026. Indeed they have some indicators reminiscent of Brawn in 2009, including major investments over the preceding years and a new engine partner. However, statistically a championship challenge is unlikely. In testing the car has visually been eye-catching. But not so much on the timing boards.
Alpine have even less reason to be optimistic. Of the teams that finished 10th or lower before a rule change, none are in the top 7 the following year. Most barely improve at all. Whilst Alpine are a much bigger team than those in the past, they’re also in a more competitive era of F1. Improvement is likely, but don’t expect too much.
Please subscribe to get updates on new posts, and check out my 2026 driver predictions using a mathematical model.
Summary
- The previous championship winners fall from the top after a major rule change, with Mercedes in 2017 being the exception.
- Rule changes often cause long term damage to the prospects of the previous world champions.
- Rule changes do provide more opportunity for the order to be shaken up. However the most likely result for any given team is that their position does not significantly improve.
- This is especially true for teams at the very bottom of the grid.
- The amount of reordering of the grid varies with each rule change and can be unpredictable.
- Looking at whether a team is improving or receding is unreliable, even if subsequent changes can be understood with hindsight.
